
本系列文章
- 12306订票客户端 FOR .NET 演示项目 【7】登录11年前 (2015-08-18)
- 12306订票客户端 FOR .NET 演示项目 【6】验证码输入11年前 (2015-08-12)
- 12306订票客户端 FOR .NET 演示项目 【5】获得余票数据11年前 (2015-06-10)
- 12306订票客户端 FOR .NET 演示项目 【4】界面框架&基础数据初始化11年前 (2015-06-08)
- 12306订票客户端 FOR .NET 演示项目 【3】流程分析和项目规划11年前 (2015-05-28)
- 12306订票客户端 FOR .NET 演示项目 【2】准备工具11年前 (2015-05-22)
- 12306订票客户端 FOR .NET 演示项目 【1】项目概况11年前 (2015-05-19)
FSLIB.NETWORK 网络库系列文章
- 12306订票助手.NET V10.6.1 发布9年前 (2016-09-01)
- 开源 FSLIB.NETWORK 库 2.2.0.010年前 (2016-08-02)
- FSLIB.NETWORK手册(1) · 基本概念和流程10年前 (2016-05-05)
- 原创FSLib.Network库更新 2.0.0 版10年前 (2016-04-05)
- 原创FSLib.Network库更新 1.6.0版(目前专注于HTTP的高性能高易用性网络库)10年前 (2015-12-13)
- 玩具系列:批量QQ群签到工具v2 (暂时屏蔽自定义位置功能)10年前 (2015-08-29)
- 玩具系列:批量QQ群签到工具(支持自定义位置)10年前 (2015-08-28)
- 12306订票助手.NET 8.0.8 发布11年前 (2015-08-21)
- 12306订票客户端 FOR .NET 演示项目 【7】登录11年前 (2015-08-18)
- 12306订票客户端 FOR .NET 演示项目 【6】验证码输入11年前 (2015-08-12)
- 12306订票客户端 FOR .NET 演示项目 【5】获得余票数据11年前 (2015-06-10)
- 原创FSLib.Network库发布 1.5 版11年前 (2015-06-09)
- 12306订票客户端 FOR .NET 演示项目 【4】界面框架&基础数据初始化11年前 (2015-06-08)
- 12306订票客户端 FOR .NET 演示项目 【3】流程分析和项目规划11年前 (2015-05-28)
- 12306订票客户端 FOR .NET 演示项目 【2】准备工具11年前 (2015-05-22)
- 12306订票客户端 FOR .NET 演示项目 【1】项目概况11年前 (2015-05-19)
- 原创FSLib.Network库发布 1.4 版11年前 (2015-05-08)
- 放一个抓取网页的信息监控小工具源码11年前 (2015-04-27)
- FSLib.Network网络库使用教程[2] 实例教程·美女们快到硬盘里来!11年前 (2015-01-30)
- FSLib.Network网络库使用教程[1] 基本使用11年前 (2015-01-19)
- 原创FSLib.Network库(目前专注于HTTP的高性能高易用性网络库)11年前 (2015-01-18)
2.1 前言
其实要做一个12306的软件版客户端,其核心奥义就是抓住重点扔掉花里胡哨的东东。抓住重点说的就是相关的API接口,花里胡哨的东西说的就是图片啊样式啊之类的东东,对于WEB来说它们是必不可少的,但是对于软件版来说这些则是累赘的东西。
由于一个WEB网站中占用体积大头的往往都是些静态的不会动的无生命物种,因此去掉这些东东既可以提高操作速度也可以减轻服务器的负载需求。虽然大型的网站都有CDN了,但是带宽也是要成本的是不是?
虽然这成本和咱并没有什么关系。
既然要用软件去实现WEB接口并实现整个流程,那么在林林总总的HTTP请求中准确地找到相关的请求并正确的识别出请求内部的各个参数就很重要了。
2.2 请求跟踪
一般而言,识别请求是个经验活,而识别请求内容并判断响应内容则是个运气活了……友情提醒下,在这之前,您还是对HTTP协议比较熟悉才方便下手。
HTTP请求跟踪在一个大型的网站上往往是一个非常痛苦的事情,虽然我们有很多成熟而且可靠的HTTP/HTTPS抓包工具可以告诉我们浏览器和服务器之间到底是怎么沟通的。但是很可惜,它们并不能告诉我们与业务逻辑有任何关系的事情。因此,当一个抓包工具获得所有和目标相关的请求时,我们需要使用另一种现代化工具来分析请求和响应数据,那就是体力劳动。
简单的说,对于HTTP/HTTPS类的跟踪,我们一般使用如下的工具:
- Fiddler:这是一个代理模式的抓包工具,基本原理是将自己模拟为一个代理服务器介入浏览器请求过程并记录所有数据。优点是简单易用且功能强大,缺点是如果目标软件不支持代理的话,那么这个工具就很难奏效了。同时,如果目标软件有自己的代理服务器设置而并非使用IE的代理设置,可能还需要先设置后才可以使用。
- 浏览器自身的抓包工具:现代浏览器(IE9+, Firefox新版或Firefox旧版+Firebug,Chrome等)都内建了较为强大的开发人员工具。其中以Firefox和Chrome的开发人员工具达到了一个特别不low的境界,对于抓包这种事儿分分钟手到擒来。使用浏览器内部的抓包工具优点是无需第三方工具,与目标网页结合十分紧密没有其它的请求干扰,易于分析,缺点就是在持久化方面会略有缺陷,比较适合及时分析。
- 第三方抓包工具。第三方抓包工具指的是例如HttpAnalyzer之类的专用于HTTP/HTTPS的抓包工具,其特点是全局,任何软件发出去的请求都能被抓到。相应的是它们往往有一些系统服务或者服务注入,可能会对系统本身有些副作用,并且有时候稳定性不够。
这里的抓包工具不包括传统意义上极其知名的工具比如Wiresherk等等,由于它们抓包的能力过于底层,所有抓到的数据实在是太繁杂了,而且特异性不强,虽然针对HTTP协议等都能做分析但是当要深入HTTP请求内部仔细查看的时候,就会显得力不从心,毕竟不是专门干那事儿的。除此以外,如果要分析的目标站点用的是HTTPS协议(比如某五位数字的网站),那么这些工具抓到的数据包往往是一堆HTTPS数据,并没有经过解密,也就很难去阅读分析了。
当记录下所有请求及相关数据时,我们需要先对请求进行分类汇总。一般来说,以下的任何请求我们都是可以忽略的(因为通常情况下它们和实际的业务并没有半毛钱关系):
- 响应状态码非200或30x的请求:比如304,50x,40x等等,一般来说意味着请求不成功。很少有业务设计会用一个不成功的响应来代表操作成功的,因此一般可以忽略
- 与目标域名差别过大且查不出任何关联的请求:随着社会化分工的进步,很多网站都会在页面用大量引用其它网站的服务和资源。如果一个业务逻辑并不牵涉到第三方,且目标请求所涉及到的网站和当前正在分析的网站存在几乎为零的关系,那么几乎可以忽略它;
- 纯粹的JS/jpg/png/css等静态文件请求:如果一个请求返回的就是一个静态资源,且路径是一个完整的路径、文件名符合其最路径的扩展名,那么基本上可以忽略,如果要分析它们的话,需要从业务入手,请求跟踪阶段可以忽略。例外的情况是如果一个请求确实是静态文件,扩展名也符合,却返回了一些cookies信息,那么这种请求一般不能忽略,人家可能是验证码神马的呢。
特别的,对于一些奇奇怪怪的网站,比如12306来说,其行事有一些奇奇怪怪的逻辑,因此对于它上面看到的请求,你能看到的不一定是有用的,你觉得没什么卵用的可能反而是有用的。总结一点就是,除非脑洞大开洞悉了他们的内心,那么最稳妥的方案就是跟着他们的请求走。
OS:虽然绝大多数情况下一板一眼跟着浏览器的请求走都不会有问题,但对于12306来说,有时候不适用。因为跟着他们请求走也有可能出错,因为有些异常的错误是你用浏览器都会很容易出现的……
2.2 浏览器工具(Chrome)
在开发过程中,推荐用Chrome浏览器,因为其比较流畅,虽然吃内存比较凶残。当然Firefox也是可以的,某些情况下比Chrome更好,但是其流畅度稍微比Chrome差一点……但是也没啥问题,只要不要用IE就行了,不是说IE不好,而是IE不够便捷强大。斯巴达会怎样?不知道。
值得一提的是,如果你没有安装过12306的根证书的话,那么Chrome中打开12306应该会看到这样的内容。
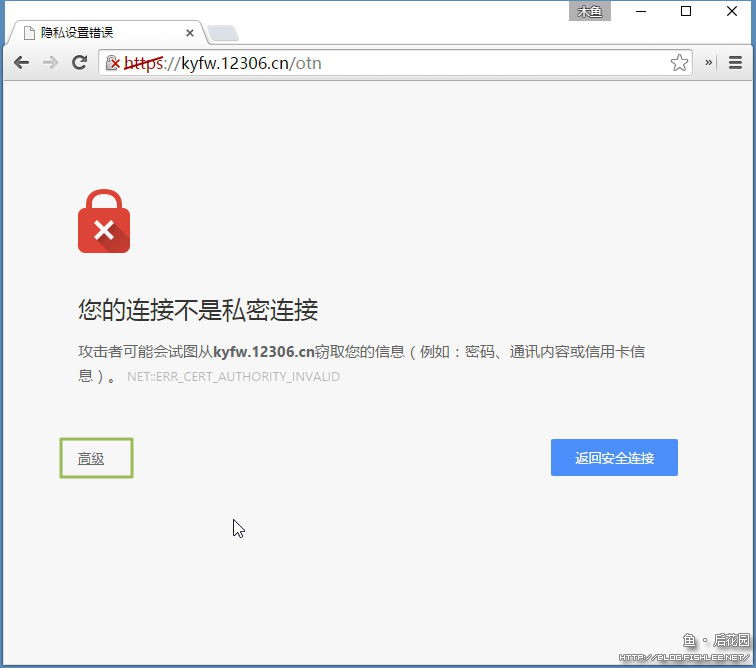
为了避免这样的问题而装12306的证书吗?可是我蠢到不会装证书,所以我每次都会点“高级”然后点“继续访问”。一样用,就是麻烦点儿。
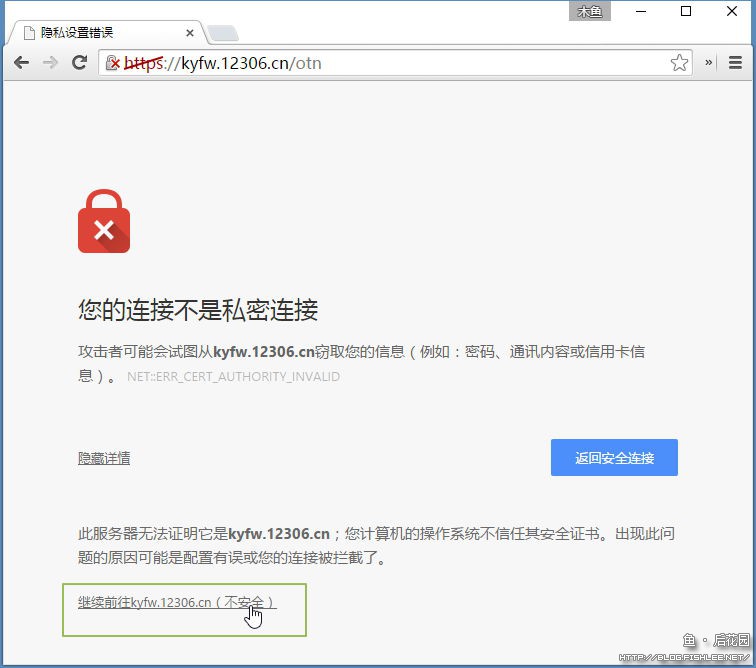
进入12306后,要想开始抓包,那就得按下F12,然后切换到“Network”面板(看不清的话请点击查看大图):
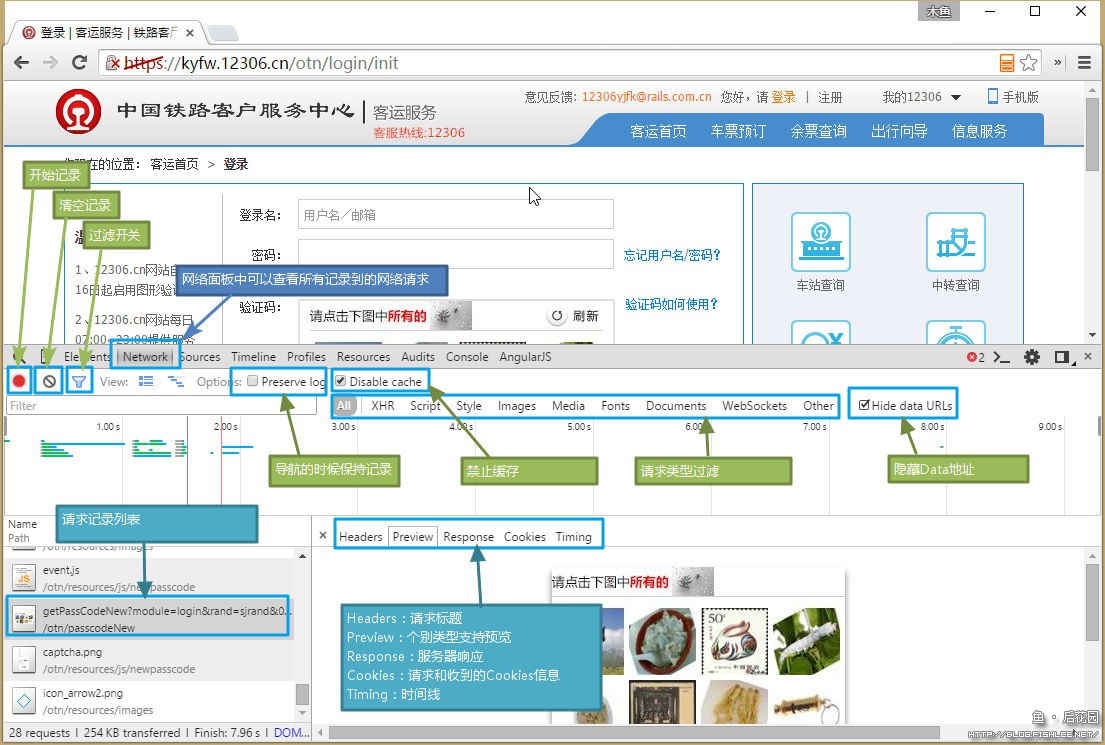
- 开始记录默认是点击的,也就是说,当开发者工具打开的时候,默认是抓包的
- 清空记录用于当前记录的请求都用过的时候,需要捕捉新的请求,这时候可以先清空当前的记录列表以给眼睛减负
- 过滤开关用于过滤或只查看指定类型的请求,虽然很多情况下并没有什么卵用,但如果你已知特定请求的类型的话,可以快速地定位请求
- 导航的时候保持记录:默认情况下当Chrome浏览到新的页面时,整个请求记录是会被清空的。开启此选项会让Chrome在导航的时候依然保存着这些记录。虽然看起来很方便,但其实没什么卵用。Chrome的记录虽然可以导出,但不容易回过头查看;而记录的之前页面的内容,你再去翻的时候会发现很多记录是无法查看响应内容的,很多时候也就失去了复查的意义。所以通常这个选项无需打开,如果需要记录完整的请求过程,可以使用Fiddler等工具。
- 禁止缓存:这个选项用于强制浏览器从服务器更新内容而忽略本地的缓存(通常是为了避免304响应)。大多数情况下这个仅在前端开发的时候或者你需要显式刷新缓存的时候用到,一般仅为了跟踪的话,不需要使用。
- 请求类型过滤:选择要显示的类型。一般选择All(全部)即可,不需要选择特定类型。当然如果你知道对应的请求就是特定类型的(比如XHR也就是Ajax请求),那么过滤一下会更容易找到
- 隐藏Data地址:一般可以勾选,不过意义不是很大,通常用于隐藏一些把图片放在DataUrl中的请求,这类请求没什么卵用看着还闹心,所以我一般都是勾着的
- 请求记录列表中可以看到具体的请求记录以及类型、时间、状态信息,一般是按照请求发出的时间进行记录的
一般对于HTTP抓包来说,使用高级一点儿的请求框架是不需要理会Cookies的,大多数情况下均为自动管理。对于服务器交互来说,最重要的就是GET/POST参数以及服务器响应。当捕捉到请求后,可以在详情中看到相关的信息。
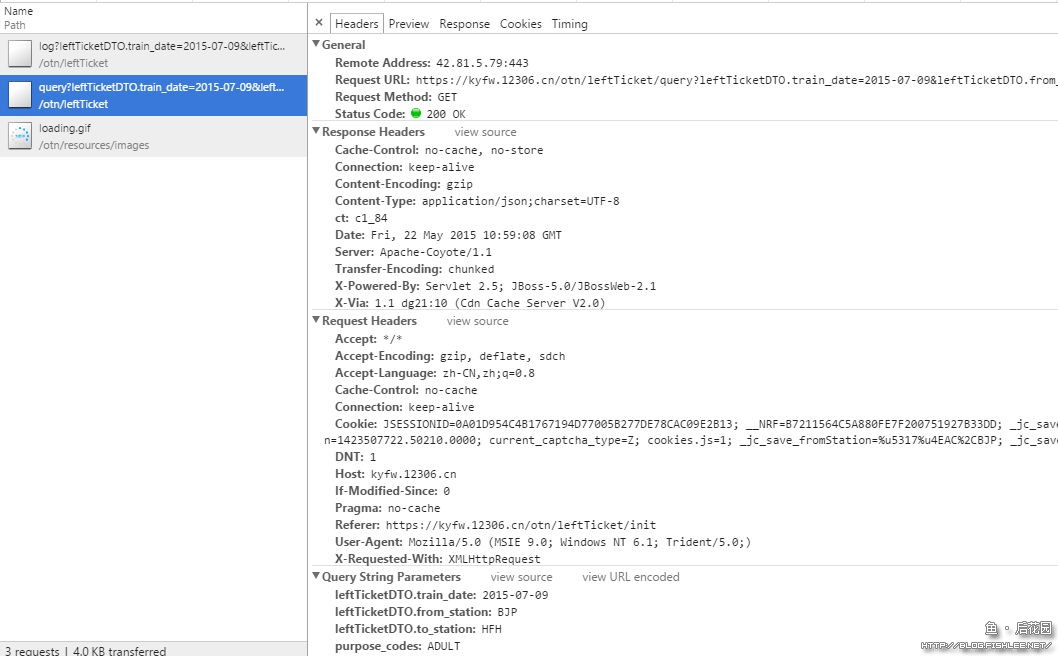
右侧从上到下的信息分别是:
- General(常规信息):包含了远程服务器地址,请求的网址、方法、服务器返回状态码等等
- Response Headers:包含了服务器响应的所有标头
- Request Headers:包含了所有由浏览器发出的请求标头,含Cookies等等
- Query String Parameters:请求参数
这个请求是通过GET发出去的,请求参数中包含了查询的参数。如果这个请求POST的,那么可能包含的是Form Data,具体根据请求来定。大部分情况下,我们需要操作的就是这部分数据了。
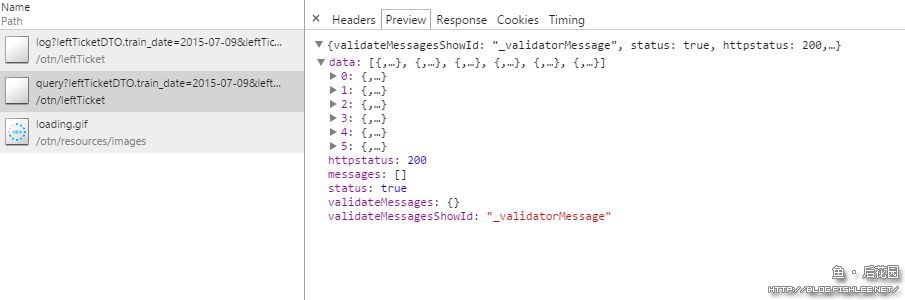
而Response中则包含了由服务器返回的数据。
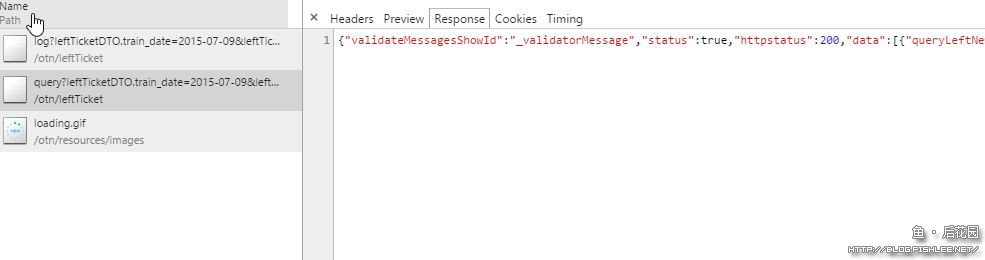
对于一些服务器响应类型,比如图片(Image)、Json数据等,可以通过Preview(预览)查看更直观的数据内容。
如果拦截到请求的时候,发现对请求的内容完全无法理解或看不懂,那么就可能需要看请求的来源了。在大部分情况下,这种需要我们进一步关注或分析的请求往往是通过脚本触发的AJAX请求。对于这些请求,我们可以通过调试(Sources)来进行调试。
提醒:进行脚本调试和阅读源码需要您对Javascript有较为了解的掌握。如果这事儿您干不来的话,不是不可以继续,而是够呛(比如12306就很难继续了)。另外Javascript是一个很大的坑,非必要的话不建议哦,虽然有那么多人会忽悠你说web会是未来的天下  。
。
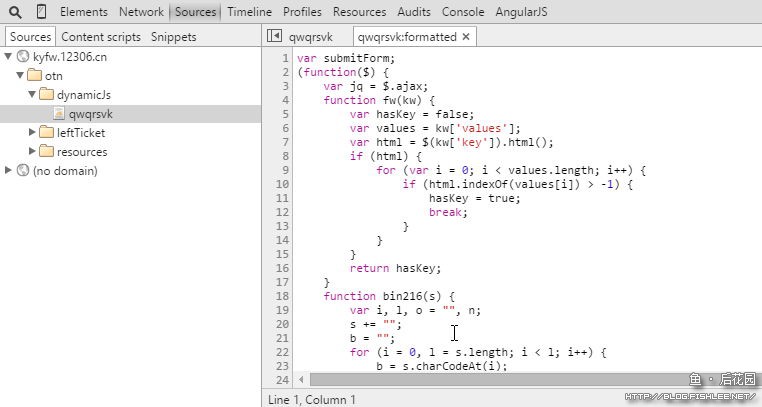
在Sources(源)中,左侧以树状接口显示了当前页面所使用到的全部资源。一般来说,我们也只关注其中的脚本而已。找到脚本后,右边会显示出其源码,还自带高大上的语法高亮功能。对于很多情况下脚本会被压缩混淆的情况,可以通过最下面的美化按钮(就是那一对儿括号)来格式化以便于阅读。
如果你需要对请求的来龙去脉进行进一步的跟踪,那么推荐使用右侧的断点功能,能看到一个XHR断点:
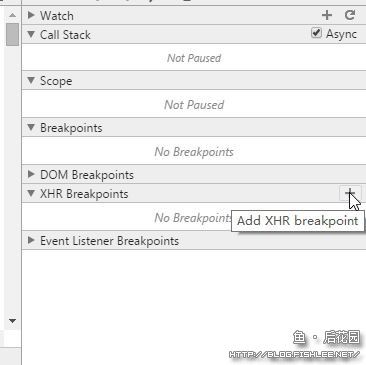
点击“Add XHR breakpoint”(添加XHR断点)后,会看到一个框框输入网址,将你要跟踪的请求地址中的一部分填进去即可。
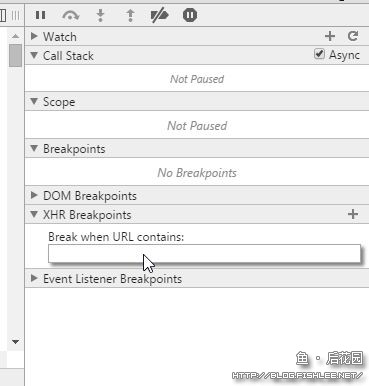
设置完成后,当对应的请求被触发时,脚本将会被强行中断在引发的位置,然后追本溯源查看回调啥的……开脑洞的时候到了。
值得一提的是,其它的国内一些壳牌浏览器都没有阉割这个开发者工具功能,个别的版本比如遨游甚至不辞辛劳地将其翻译成了中文。虽然翻译成中文这种吃力不讨好的事儿我很多年前干过,于是不得不给他们的程序猿们点赞,虽然这并没有什么卵用:他们的核心实在太老了,还是建议用更新版的浏览器。除此以外,爱用啥浏览器只要能抓包,那都是您的事儿了嘞。
2.3 抓包工具(Fiddler)
Fiddler是一个很小很优秀很方便用的抓包工具,简直是居家必备啊。
Fiddler官网下载安装Fiddler需要安装.NET FRAMEWORK。这会让不少软黑不爽……另外就是Fiddler是英文版的,需要点阅读鸟语的能力。许久以前我汉化过一次,但那次无疾而终,因为这货是VB.net写的,没有提供本地化机制,汉化极其麻烦还不彻底……
安装启动Fiddler后我们需要先进行设置,因为默认情况下是不会对HTTPS请求解密的,也就无法看到HTTPS请求内容了。为了跟踪调试12306,我们需要让它可以对HTTPS进行解密。
PS一下,这个其实就类似于中间人攻击。
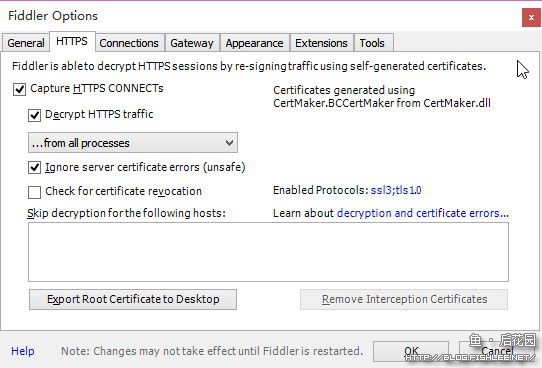
设置如上图所示。在这中间会要求你安装证书等等,点确定即可,当然得安装。末了去“Connections”中看看当前Fiddler使用的端口,以便于当浏览器或软件不是使用IE默认代理的时候手动设置代理。
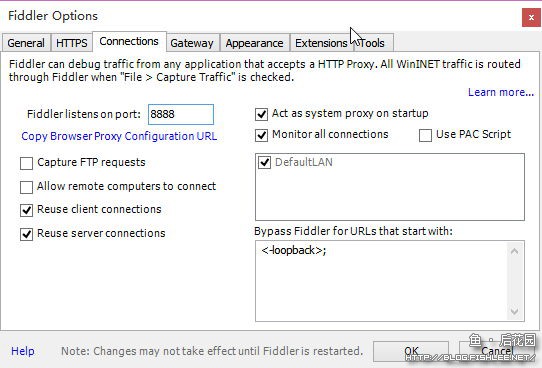
如上图所示设置后,Fiddler同时可以作为代理服务器使用,在手机上设置代理服务器后,可以抓到手机浏览器的请求喔,一般人我不告诉他 
如果设置无误,那么在浏览器中访问12306后,即可看到Fiddler中保存了所有的记录。

界面上可查阅的东西很多,但是好在比较直观,且和Chrome中的信息差别不大,所以各位就左手拎着一部英语词典将就看看吧,捣鼓捣鼓就差不多了。一般关注的内容是左侧的记录列表和右侧Inspectors中的Headers(请求或响应标头)、TextView(文本数据)、WebForms(WEB表单和查询数据)。
建议在开始之后的事情之前先玩转Fiddler,包含以下功能:
- Replay:重发请求
- 拖动请求到Composer中克隆请求
- 在Composer中手动编辑请求并发送
- 通过File菜单保存、加载请求
- 通过AutoResponsder来拦截或自动对请求做出响应
以上内容都是比较常用的功能,不会的话请搜索相关的资料,必要的时候可以脑洞大开地测试……
Fiddler中记录可能比较多,如果有干扰的话,建议通过右侧的Filter面板来进行过滤。
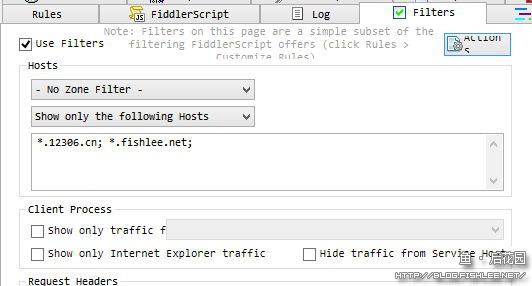
使用主机过滤后即可只显示指定的域名上的请求,比较易于跟踪调试。其它过滤选项也请自行查看 
友情提示:如果你使用的浏览器并非IE的话,可能会遇到浏览器中的内容可能无法在Fiddler中抓到的问题。默认情况下Chrome会使用IE浏览器的代理设置,但如果你使用了一些第三方扩展(如SwitchyOmega/SwitchSharp等)的话,可能会接管Chrome的代理设置导致默认不使用系统代理,这种情况下需要你在相应代理扩展中手动配置代理为Fiddler的监听端口。如果第三方浏览器、软件拥有独立的代理设置,也可能会有影响。
2.4 本章就到这里,拜拜,再见~
感谢阅读本文,欢迎扫描下方二维码关注鱼的公众号(微信内长按识别哦) 

Fiddler 这个工具不可以在抓Chrome的https的数据了?
可以啊,不过前提是它得是浏览器的代理服务器。
持续关注中,很期待下一节内容,和我现在的项目正相关。大赞
看完了。 表示安装Fiddler完之后。 Fiddler没有抓取Chrome浏览器的数据。 幸好我装了SwitchyOmega。 然后添加了一个情景模式,代理内容填写127.0.0.1:8888. 然后就抓取到了。
表示那里可以写详细点~~~~~
其实如果你没安装那个扩展,就会发现没那个问题了。
你没看友情提示嘛
那个是我看到他在说之后才加上去的