
我是路标
0x1. 起因
话说,今天下午群里面有个同学求助一段代码。

他想问的是,这个 tempimei[j * 2] - 0x30 是啥子意思?
0x2. 其实这是很常见的一种写法
我们留意到 tempimei 这个变量其实是一个字符串。在.NET中,对一个字符串取索引,则是取出对应的字符。
字符可以隐式转换为int,所以tempimei[j*2]-0x30的意思是,将j*2索引位置的字符转换成int后减去0x30。为什么要这么减呢,我们参考一下ASCII表:
| 二进制 | 十进制 | 十六进制 | 字符 |
|---|---|---|---|
| 101111 | 47 | 2F | / |
| 110000 | 48 | 30 | 0 |
| 110001 | 49 | 31 | 1 |
| 110010 | 50 | 32 | 2 |
| 110011 | 51 | 33 | 3 |
| 110100 | 52 | 34 | 4 |
| 110101 | 53 | 35 | 5 |
| 110110 | 54 | 36 | 6 |
| 110111 | 55 | 37 | 7 |
| 111000 | 56 | 38 | 8 |
| 111001 | 57 | 39 | 9 |
由以上表格可以看出,0x30其实就是0的ASCII码。那么把一个为数字的字符减去它呢,那就恰好是这个字符所实际代表的数字值了。比如 '4'-0x30=0x34-0x30=4,这是多么巧的巧合啊。

0x3. 其实上面的这个问题是小问题
那什么是大问题呢?
大问题是这个代码的性能问题。根据这位同学的反应,这个代码其实最早是从一个Java程序翻译过来的。而Java的程序代码,如下所示。

虽然Java的语法在我看起来很LOW,但是不得不承认的是,Java到C#的Port相当精准,甚至字符转数字的时候还有那么点儿小机灵在里面(Java的就是直接用Integer.parseInt的。咦,为啥既然已经是Integer去Parse了为啥又要说parseInt?咦?为啥我要说又?) 
据说这个Java版本的带来来源于这个CSDN博客。然后我过去看了一下,还真是。
然后根据他的表述,这个其实已经有专门的软件做这事儿了,喏。
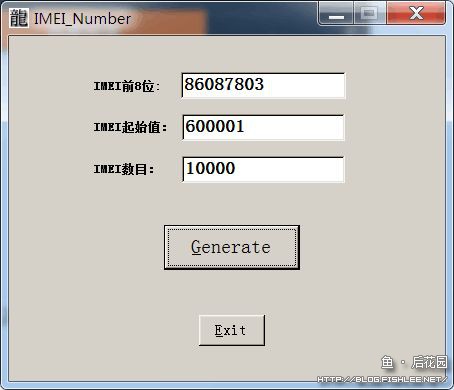
然后呢,这个程序呢,最大的问题呢,就是慢。
辣么究竟有多慢呢,大概呢,在他的I3笔记本上,生成一万个号大概需要三分多钟(原话如是说,开始生成后就会一直无响应,看文件慢慢涨到160多K的时候,就完成了……)。真的好慢喔 
我觉得真的好慢,然而我并没有这个Java版本的,所以无从考证。不过我倒是拿到一个C#版本的,测试了一下,好像并没有他说的那么慢,可能是因为Java本身就辣么慢吧。
C#版本这里提供一个下载,有兴趣的同学可以下载回去看看。
IMEI生成器源码-第三方-C#我们来看一下C#版本的核心代码。
string tempimei = "";
string imei = "";
int temp = 0;
string AfilePath = "";
long num = Int64.Parse(textBox1.Text.ToString(), System.Globalization.NumberStyles.Integer);
int step = Int16.Parse(textBox4.Text.ToString(), System.Globalization.NumberStyles.Integer);
int count = Int16.Parse(textBox5.Text.ToString(), System.Globalization.NumberStyles.Integer);
saveFileDialog1.Filter = "txt files(*.txt)|*.txt";//设置保存文件类型
if ((saveFileDialog1.ShowDialog() == DialogResult.OK))
{
AfilePath = this.saveFileDialog1.FileName;
int[] d = new int[2];
for (int i = 0; i < count; i++)
{
tempimei = "";
if (i != 0)
{
num += step;
}
tempimei = Convert.ToString(num, 10);
temp = 0;
for (int j = 0; j < 7; j++) //计算校验位
{
d[0] = tempimei[j * 2] - 0x30;
d[1] = (tempimei[j * 2 + 1] - 0x30) * 2;
temp = temp + d[0] + (d[1] / 10) + (d[1] % 10); //计算校验位
}
temp = 10 - (temp % 10);
if (temp == 10)
{
temp = 0;
}
tempimei += Convert.ToString(temp, 10);
imei += tempimei + Environment.NewLine;
}
FileStream fs = new FileStream(AfilePath, FileMode.Create);
byte[] writeMesaage = Encoding.GetEncoding("GB2312").GetBytes(imei);
fs.Write(writeMesaage, 0, writeMesaage.Length);
fs.Close();
}
核心代码和之前贴出来的并没有很大的差别,然后还附赠了一个很友好的算法说明。

对照这个说明,再去看它的计算代码,就一目了然了,这里有几个细节。
- 输入一共是14位的数字,结果的15位最后1位是校验和
- 前14位数字俩俩配种,然后算出来一个数字,最后所有的数字总和经过一定的处理后,作为校验码
- 算法中,俩俩配种这个过程,使用的是将原来的数字转换为字符串再分别按位处理的方式进行运算的
- 生成的最后写入文件,此程序使用的方式是将所有的结果依次连接为一个巨大的字符串然后一次性写入文件(
imei)。这个方式我就不说了,想想100W个结果时的恐怖好了……
在类似的需求中,当要求按位处理一个数字时,将其转换为字符串再按索引处理是一个极为常见的思路。然而这个思路最大的问题就是字符串的转换损耗,伴随着GC的压力。
由于字符串是一个较为特殊的对象,在频繁的字符串创建、取索引再重新转为数字的过程中,会伴随着大量无用的对象创建以及字符处理。就算是字符串驻留也不能完全抵消此类的影响。
因此,想要提高性能,避免字符串大量的创建是必须做到的。
先来看看这个C#版的性能。根据它的算法,抽出以下的核心代码,将量设置大一点(100W),跑一下看看大概需要多久。
public static void Main(string[] args)
{
var count = 1000000;
var imei = "";
var tempimei = "";
var num = 86087803000000L;
var step = 1;
var temp = 0;
var st = new Stopwatch();
st.Start();
int[] d = new int[2];
for (int i = 0; i < count; i++) {
tempimei = "";
if (i != 0) {
num += step;
}
tempimei = Convert.ToString(num, 10);
temp = 0;
for (int j = 0; j < 7; j++) { //计算校验位
d[0] = tempimei[j * 2] - 0x30;
d[1] = (tempimei[j * 2 + 1] - 0x30) * 2;
temp = temp + d[0] + (d[1] / 10) + (d[1] % 10); //计算校验位
}
temp = 10 - (temp % 10);
if (temp == 10) {
temp = 0;
}
tempimei += Convert.ToString(temp, 10);
imei += tempimei + Environment.NewLine;
}
st.Stop();
Console.WriteLine("生成完成。100W个序列生成用时 " + st.ElapsedMilliseconds + "毫秒.");
Console.ReadKey();
}
最后结果相当震撼,这个程序用了大概……我也不知道,因为我从凌晨3点30分等到凌晨5点30分它也没跑完,我实在没有等它的耐心了……并且如果你有耐心一直看的话,会发现这货的内存占用波动非常大,这得归功于大量字符串的生成和销毁。
以下是在Process Explorer中显示的性能曲线。另外从图中可以看出,除了内存占用波动很大以外,CPU密集型的程序居然只占了不大的CPU,这是因为GC压力导致的运行效率过低。
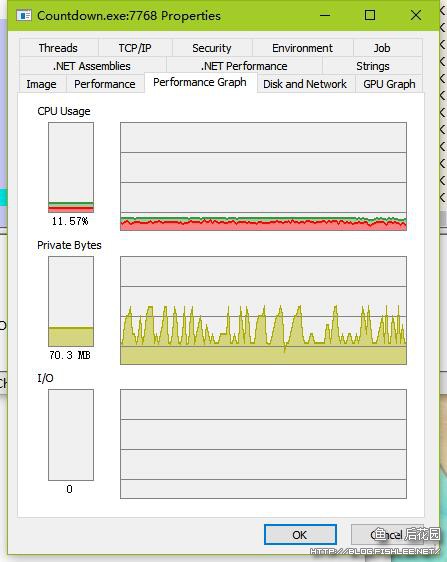
……果然太慢,慢到了几乎没法用的地步…… 
0x4. 开始重构
简单粗暴点。干嘛那么温柔。
根据需求,将整个过程分解为三个模块。
- 迭代模块,根据需求,生成指定的IMEI序列
- 验证模块,将输入的IMEI编码进行校验并附上校验和
- 文件模块,将最终的结果写入文件中
为了避免大量字符串的创建消耗,决定将输入输出的结果全部使用数字来表示,并尽可能避免字符串创建 
验证模块
简单粗暴点,直接上代码,看注释。
/// <summary> /// 计算输入的IMEI码校验和,并返回带有校验和的IMEI编码 /// </summary> /// <param name="imei">不带校验和的14位IMEI编码</param> /// <returns>带有校验和的15位IMEI编码</returns> internal static long Generate(long imei) { //创建临时副本。在计算过程中,变量会被修改 var currnet = imei; //将数字分组,俩俩一组,则索引为0到7.使用 LINQ创建一个0到7的序列,并遍历 //temp为最终的校验和,使用Aggregate进行迭代 var checksum = Enumerable.Range(0, 7).Aggregate(0, (temp, index) => { //不使用字符串取索引再转回数字的方式,那样无用功太多。直接使用数字取余计算 //由于取余时个位数(相当于原来的第二位)是先获得的,因此需要注意顺序 var d1 = (int)(currnet % 10) * 2; //此处相当于将数字序列整体右移一位,以便于继续取十位上数字 currnet = currnet / 10; //下同 var d0 = (int)(currnet % 10); currnet = currnet / 10; //对校验和进行迭代 return temp + d0 + d1 / 10 + d1 % 10; }); //原算法中的计算 checksum = 10 - (checksum % 10); if (checksum == 10) checksum = 0; return imei * 10 + checksum; }
迭代模块
……这个就更没有技术含量了,我相信我不写注释乃们也看得懂。
internal static IEnumerable<long> GenerateSingleM1(long start, int step, int count) { var list = new List<long>(count); for (int i = 0; i < count; i++) { list.Add(Generate(start)); start += step; } return list; }
写入文件
写入文件摒弃一次性写入方案,因为当数量一多(比如100万)的时候,光连接字符串就能弄死你,还不如一行行写入呢。
internal static void Write(string path, IEnumerable<long> data) { var fs = new StreamWriter(path); foreach (var item in data) { fs.WriteLine(item.ToString()); } fs.Close(); }
性能测试
以上是不是很没有技术含量?简单思路就是将所有字符串操作干掉,改为数学运算。
我们来看一下同样的100W次生成,这个程序耗时多少。
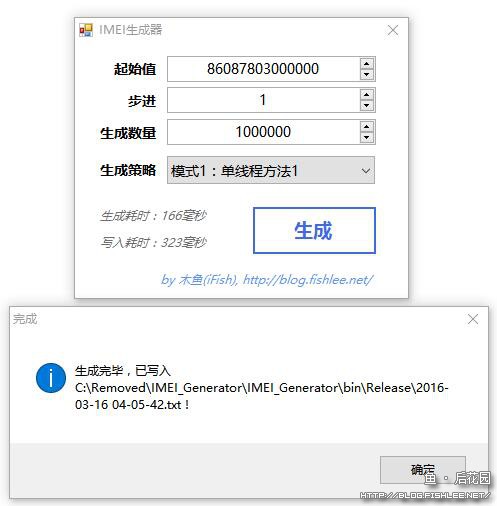
是的,你没看错,166毫秒生成100W数据。
思路很简单,效果很赞 

0x5. 继续重构
到这里,你以为我就会收手了吗?图样图森破

现在我回过头再去看那个校验和算法,感觉虽然用LINQ来生成序列看起来很时髦,但其实是脱裤子放屁,并不是特别需要。不仅如此,它还导致新建了一个序列的开销。
所以要不直接简单粗暴原始点?
internal static long Generate1(long imei) { var current = imei; var checksum = 0; //去掉LINQ,变为最原生的循环 for (int i = 0; i < 7; i++) { var d1 = (int)(current % 10) * 2; current = current / 10; var d0 = (int)(current % 10); current = current / 10; checksum += +d0 + d1 / 10 + d1 % 10; } checksum = 10 - (checksum % 10); if (checksum == 10) checksum = 0; return imei * 10 + checksum; }
让我们再来测试一下。
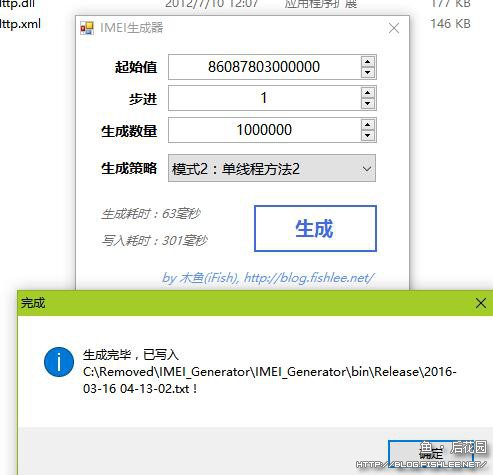
63毫秒完成100W数据生成,结果略狂野啊 
0x6. 继续重构!
到这里就已经是极致了吗?非也!
我们要并行化!利用多核并行运算!
话说这个我一开始都没想起来,还是受人启发的……
internal static IEnumerable<long> GenerateParallelM1(long start, int step, int count) { var list = new List<List<long>>(); //由系统自动分区计算 Parallel.ForEach(Partitioner.Create(start, start + count), _ => { var tlist = new List<long>(count); for (var i = _.Item1; i < _.Item2; i++) { tlist.Add(Generate(i)); } lock (list) { list.Add(tlist); } }); //由于并行化的时候,返回的顺序不一定是按照你期望的顺序,所以这里需要先排序一次,以保证顺序和期望的一致 return list.OrderBy(s => s[0]).SelectMany(s => s); }
考虑到我们之前有过俩方案,于是再俩俩随机滚床单之后,就有四组CP了。然后我们分别测试一下并行的性能。
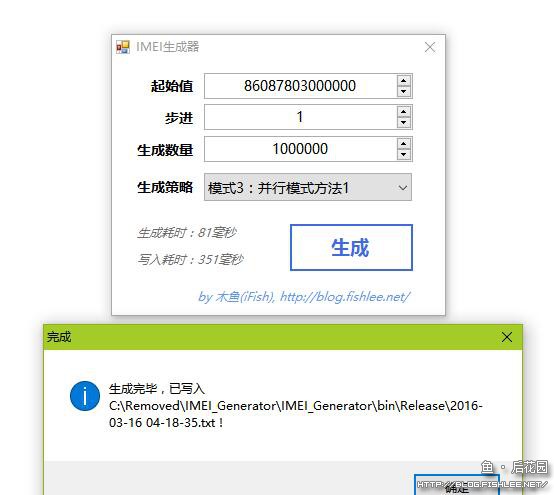
耗时为原耗时(166毫秒)的一半。
那么方法二嘞?
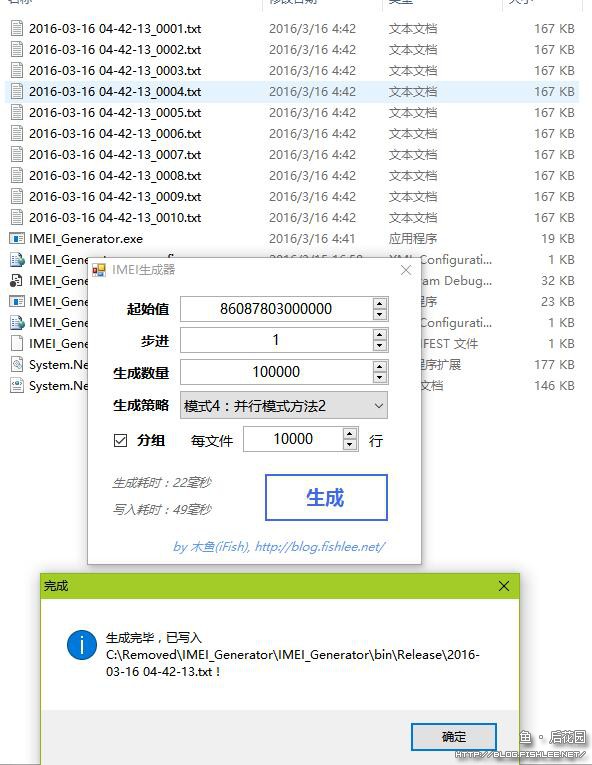
17毫秒生成数据,耗时只有三分之一。
0x7. 总结
| 类型 | 算法1 | 算法二 |
|---|---|---|
| 单线程 | 166毫秒 | 63毫秒 |
| 并行运算 | 81毫秒 | 17毫秒 |
毫无疑问,算法二+并行最优秀,而且数据量越大,优势越大。
0x8. 附加
人家说希望一次生成一百万,但是每一万生成一个文件。
既然都做到这里了,不妨加上咯……
internal static void Write(string path, IEnumerable<long> data, int piece = 0) { if (piece == 0) { var fs = new StreamWriter(path); foreach (var item in data) { fs.WriteLine(item.ToString()); } fs.Close(); } else { var lineCount = 0; var fileIndex = 1; var directoryName = Path.GetDirectoryName(path); var fileName = Path.GetFileNameWithoutExtension(path); var fileExtension = Path.GetExtension(path); StreamWriter fs = null; foreach (var item in data) { if (fs == null) { fs = new StreamWriter(Path.Combine(directoryName, fileName + "_" + (fileIndex++).ToString("0000") + fileExtension)); lineCount = 0; } fs.WriteLine(item.ToString()); if (++lineCount >= piece) { fs.Close(); fs = null; } } if (fs != null) fs.Close(); } }
0x9. 源码
呐,不是很重要的玩意儿,拿去吧~授人以渔,也要授人以鱼
IMEI生成器 by iFish 源码包 IMEI生成器 by iFish 可执行包

感谢阅读本文,欢迎扫描下方二维码关注鱼的公众号(微信内长按识别哦) 

膜拜大佬,感谢大佬
下载链接失效了
看着看着笑了出来,博主真的是好玩~,感觉很认真
感谢楼主
最后两幅图片里的测试数据量是 10W 而不是 100W
太棒啦,正在学并行的说。
internal static long Generate1(long imei)
{
var current = imei;
var checksum = 0;
//去掉LINQ,变为最原生的循环
for (int i = 0; i < 7; i++)
{
var d1 = (int)(current % 10) * 2;
current = current / 10;
var d0 = (int)(current % 10);
current = current / 10;
checksum += +d0 + d1 / 10 + d1 % 10;
}
checksum = 10 – (checksum % 10);
if (checksum == 10)
checksum = 0;
return imei * 10 + checksum;
}
看浏览器版本———————————————————
哈哈

牛B啊,虽然没看懂,但感觉好刁啊
好吧,是六点多
话说这到底是几点发的,我这显示三个小时之前推算一下就是早上四点到五点之间
大大,弱弱的问一句,你都学了什么书籍,才会有你这样的渊博
测试
鱼妈威武。 半夜不谁家,凑15字。
鱼妈威武。 半夜不谁家,凑15字。