
我是路标
FSLIB.NETWORK网络库系列文章
- 12306订票助手.NET V10.6.1 发布9年前 (2016-09-01)
- 开源 FSLIB.NETWORK 库 2.2.0.010年前 (2016-08-02)
- FSLIB.NETWORK手册(1) · 基本概念和流程10年前 (2016-05-05)
- 原创FSLib.Network库更新 2.0.0 版10年前 (2016-04-05)
- 原创FSLib.Network库更新 1.6.0版(目前专注于HTTP的高性能高易用性网络库)10年前 (2015-12-13)
- 玩具系列:批量QQ群签到工具v2 (暂时屏蔽自定义位置功能)10年前 (2015-08-29)
- 玩具系列:批量QQ群签到工具(支持自定义位置)10年前 (2015-08-28)
- 12306订票助手.NET 8.0.8 发布11年前 (2015-08-21)
- 12306订票客户端 FOR .NET 演示项目 【7】登录11年前 (2015-08-18)
- 12306订票客户端 FOR .NET 演示项目 【6】验证码输入11年前 (2015-08-12)
- 12306订票客户端 FOR .NET 演示项目 【5】获得余票数据11年前 (2015-06-10)
- 原创FSLib.Network库发布 1.5 版11年前 (2015-06-09)
- 12306订票客户端 FOR .NET 演示项目 【4】界面框架&基础数据初始化11年前 (2015-06-08)
- 12306订票客户端 FOR .NET 演示项目 【3】流程分析和项目规划11年前 (2015-05-28)
- 12306订票客户端 FOR .NET 演示项目 【2】准备工具11年前 (2015-05-22)
- 12306订票客户端 FOR .NET 演示项目 【1】项目概况11年前 (2015-05-19)
- 原创FSLib.Network库发布 1.4 版11年前 (2015-05-08)
- 放一个抓取网页的信息监控小工具源码11年前 (2015-04-27)
- FSLib.Network网络库使用教程[2] 实例教程·美女们快到硬盘里来!11年前 (2015-01-30)
- FSLib.Network网络库使用教程[1] 基本使用11年前 (2015-01-19)
- 原创FSLib.Network库(目前专注于HTTP的高性能高易用性网络库)11年前 (2015-01-18)
之前介绍过网络库的基本信息和基本使用情况。后面准备来写一点实例教程。
本来想着先写QQ空间到WordPress导出工具的(毕竟这个博客之前的文章也都是这么导过来的),可是突然觉得不是很吸引人,毕竟有这种需求的人太少了……上次有人发了一个代码片段抓美女图的,我不禁眼前一亮……嗯哼,还是得从本质出发啊,凡事抓住最根本的需求,方能引人入胜。所以我决定抓住 书生本~色 这个关键因素……写个抓美女图的工具吧。
1.起因
事情的起因如上所述,其实还有个引子,就是之前有同学在群里发了一个Code Snippet,在OSCHINA上,是一个C#的一段代码,用来抓妹子图的。当然很容易看明白,不过我还是好奇地去看了一下这个网站……矮油我去,这个地址的图片质量还都蛮高的嘞。好了来个爬虫吧。
捎带借妹子来作为自己网络库的实例,想想我也是蛮无耻的  ,应该会有不少淫贼手贱点进来了……嗯哼。
,应该会有不少淫贼手贱点进来了……嗯哼。
再说了,这些美女们基本上都逃离不了PS的魔爪啊……看多了只会让自己的人生观畸形世界观败坏节操粉碎性骨折……对生活充满绝望……因为离开了特效和后期,效果是很不一样的……
先来预览。
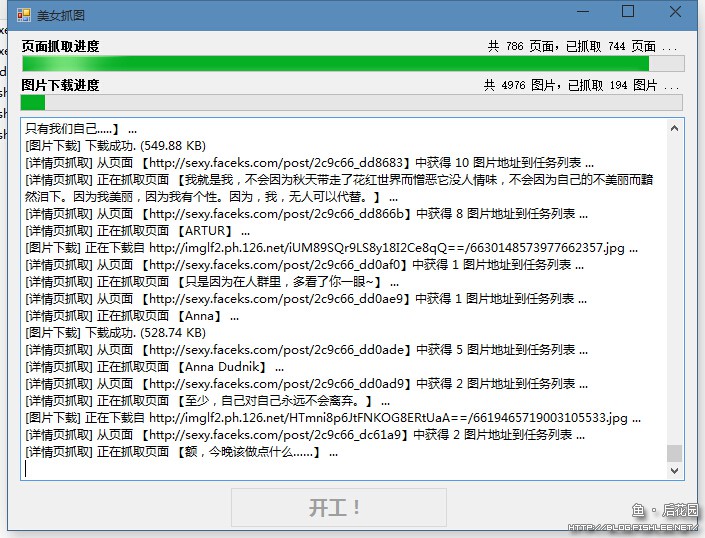
是不是仿佛看到了妹子在向你招手?那继续吧……
2.设计目标
虽然只是写一个例子,但还是写得完善点拉,写得拖拖拉拉地残破不全的不是俺老孙的风格  。
。
所以先假定有以下目标:
- 需要有任务记录,可以做增量下载(如果网站有更新,可以增量下载而不是全部重新下载)
- 可以断点继续(如果有几千个任务哐当哐当下了半天结果程序出错了,下次启动可以从断掉的地方继续下载,而不是从头下载
- 最好能稍微友好点,不能因为是个例子就老是假死之类的
好了。定下了这些目标,就让俺老孙先看看这个网站到底是啥怪物  。
。
3.网站分析
简单分析了一下之前的那个代码段,最终发现其实本身访问的是……而它究竟和网易的LOFTER有啥关联恕我真的不知道……所以咱就不去关心了吧。
这个网站是个很基本的CMS网站,列表页——详细页——大图,就是这么简单直接外带粗俗暴力  。
。
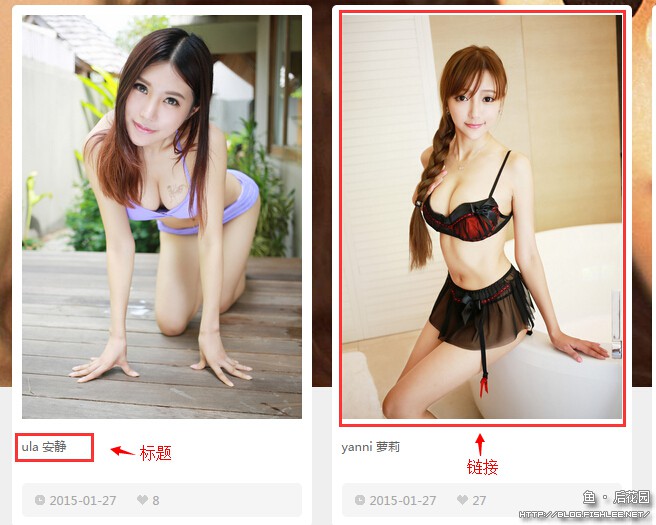
对于这样简单到没有底蕴可言的美女,我们一般可以直接查她的裙底……不对,是对于这样简单到没有底蕴可言的美女,我们一般可以直接查它的源码。

上图标记红圈儿的地方分别是标题和地址。
PS一下,之前的那个代码只抓了列表页的图……其实详细页的图更多,但是它完全忽略了……
而进入详情页后,会有一大堆图片向你招手。
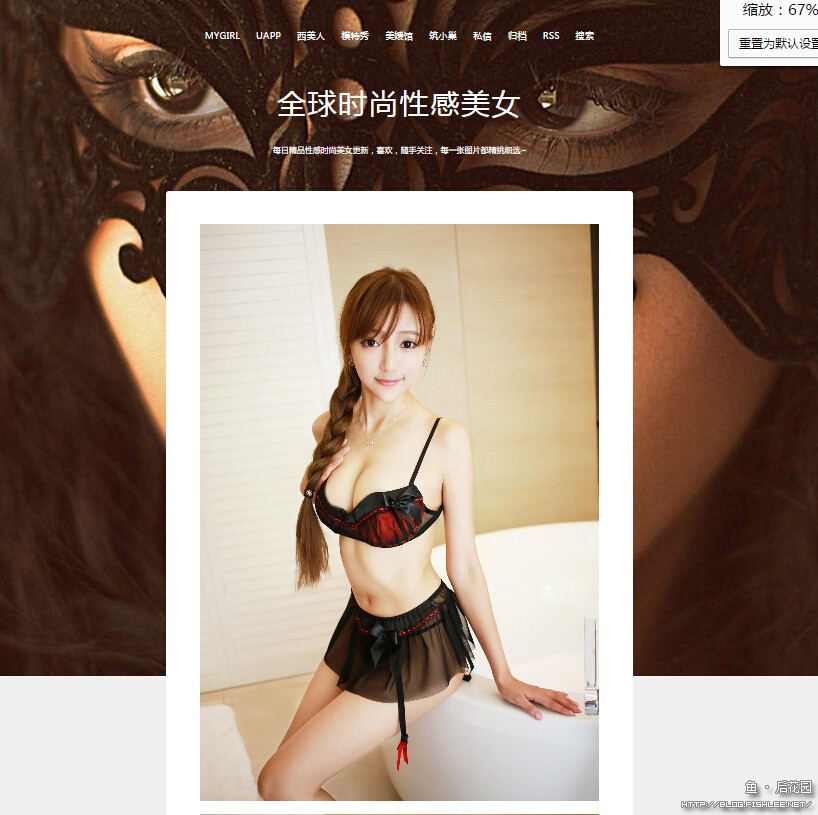
额……回来,收起你正准备右击准备另存的鼠标……咱要做的是正经事儿。
老规矩看源码,这个源码如同它的列表页一样,简单明了,和这个美女的衣服一样简单…… 

图中能看到地址有俩,一个是图片本身地址,一个是bigimgsrc地址。根据经验猜测属性里面的那个才是大图,虽然这里俩地址一样。猜测他们可能原来准备弄缩略图的,后来觉得好麻烦,反正看到这里的基本上都肯定要戳大图的,不如直接用大图好了这样点大图的时候随点随开,那用户体验不要太爆表…… 
嗯好了,网站基本上看完了,动手吧。
动手之前再回去看看这个小美女……啧啧啧啧……看得我准备放弃江山了…… 
3.基本规划
根据网站实际情况以及咱的目标结合分析呢,暂定出这样的方案……
- 把抓取任务分解为三类:详细页列表抓取;图片列表抓取;图片下载;
- 每个任务放在不同的线程中单独执行
- 使用全局的上下文数据进行相关任务的存储和调度
- 程序所需要的数据保存在同目录下的
data目录中,下载的结果放在同目录下的下载目录中 - ……尽量少写代码,无关紧要的东西先放放了,只是为了抓个数据又不是为了把她们娶回家


完毕了,现在开始干正事儿。
4.创建项目
相信你对创建项目熟能生巧,所以这里就不多废话了(其实是我懒 )。建立项目后先右击项目节点管理包,搜索iFish后安装network.fishlee.net。
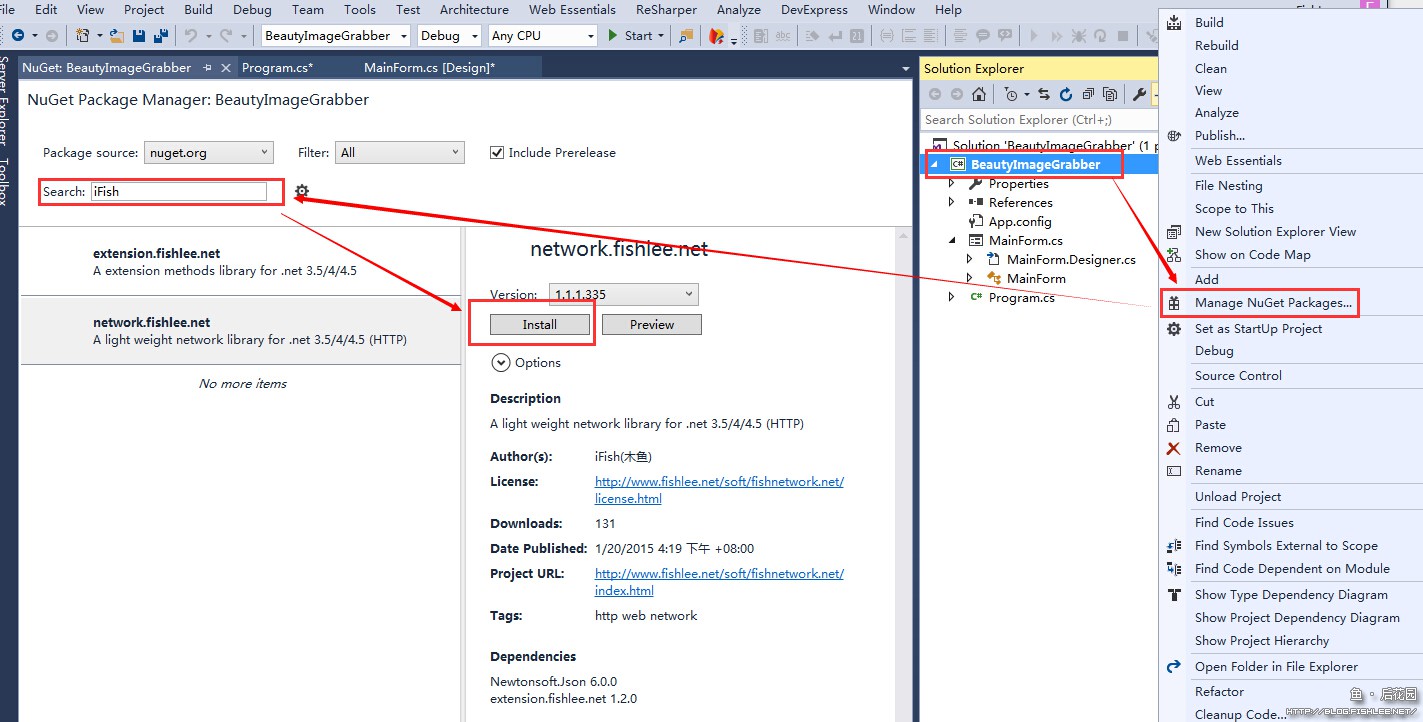
如果你的Visual Studio不是VS2015,那可能看到的和上面界面不一致,不过总的来说没啥差别。
这个包会同时安装 Newtonsoft.Json 以及 extension.fishlee.net 两个包,安装后前一个包由依赖解析而来的可能不是很新,可以先更新一下。
5.界面设计
从简化设计出发,界面设计很简单。
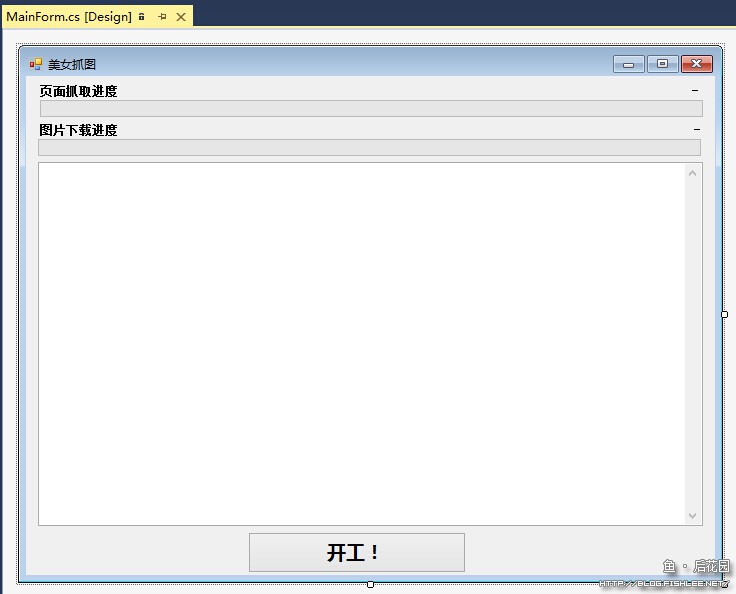
……或者可以参照下图?这图看起来有点密恐
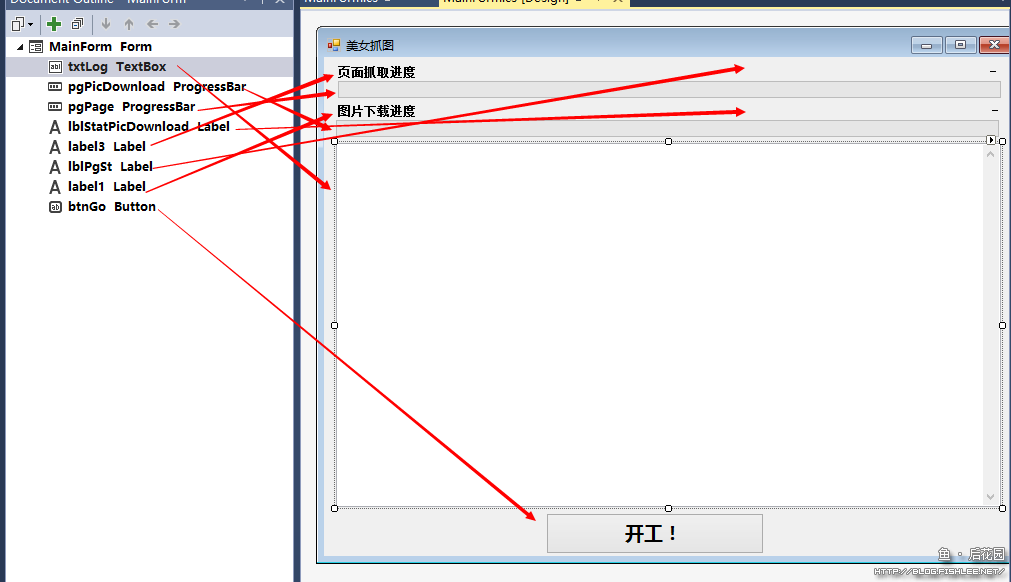
4.功能编写
4.1 任务数据定义
先创建上下文数据保存类,用于保存和任务相关的数据。
考虑到我们之前使用了多个线程,那么可能需要两个类来传递相关的任务信息。先创建一个任务类保存下载后的图片详细信息(我们记录保存的位置,做事儿要有迹可循……)。
class ImageDownloadTaskInfo { /// <summary> /// 实际的保存位置 /// </summary> public string Location { get; set; } }
然后我们再创建一个类,用来保存图片下载任务。因为一个页面可能会有好多图,我们需要把每个图都创建成一个任务丢给下载线程去努力奋斗。
/// <summary> /// 图片下载任务 /// </summary> class ImageDownloadTask { /// <summary> /// 图片地址 /// </summary> public string Url { get; set; } /// <summary> /// 下载目标 /// </summary> public string DownloadRoot { get; set; } public ImageDownloadTask(string url, string root) { DownloadRoot = root; Url = url; } public ImageDownloadTask() { } }
考虑到列表页后面的详情页也是需要挨个爬的,所以对于实际的详情页我们也做成一个任务列表。
class PageTask { /// <summary> /// 标题 /// </summary> public string Name { get; set; } /// <summary> /// 地址 /// </summary> public string Url { get; set; } /// <summary> /// 下载目标 /// </summary> public string Root { get; set; } /// <summary> /// 包含的图片信息 /// </summary> public Dictionary<string, ImageDownloadTaskInfo> Images { get; set; } public PageTask(string name, string url) : this() { Name = Utility.RemoveInvalidCharacters(name); Url = url; } public PageTask() { Images = new Dictionary<string, ImageDownloadTaskInfo>(StringComparer.OrdinalIgnoreCase); } }
这里面有个 RemoveInvalidCharacters 函数,这个函数是为了将创建文件夹时无效的字符串进行过滤,定义如下(需要引用 System.Web)。
static Regex _removeInvalidCharReg = new Regex("[" + Path.GetInvalidFileNameChars().JoinAsString("").Replace(@"\", @"\\") + "]");
/// <summary> /// 移除路径中无效的字符 /// </summary> /// <param name="name"></param> /// <returns></returns> public static string RemoveInvalidCharacters(string name) { if (String.IsNullOrEmpty(name)) return name; name = HttpUtility.HtmlDecode(name); name = Regex.Replace(name, @"(^\s+|[\r\n]|\s+$)", ""); return _removeInvalidCharReg.Replace(name, "_"); }
嗯,最后我们来创建一个数据仓库。我们的数据仓库需要保存哪些信息呢?
- 当前的状态:是否已经全部索引完成。如果全部索引完成,那么每次检查的时候只需要看看有没有更新就行了;否则就需要将所有的页面全部爬一遍
- 已经检索过的详情页列表以及其相关信息
- 正在等待检索的详情页列表
- 已经擒拿的美女的列表以及信息
- 准备擒拿的美女列表
结合以上任务需求,编写如下的数据存储类。
class TaskData { /// <summary> /// 已下载的页面列表 /// </summary> public Dictionary<string, PageTask> PageDownloaded { get; set; } /// <summary> /// 等待下载的页面队列任务 /// </summary> public Queue<PageTask> WaitForDownloadPageTasks { get; set; } public Dictionary<string, ImageDownloadTaskInfo> DownloadedImages { get; set; } /// <summary> /// 准备下载的图片列表 /// </summary> public Queue<ImageDownloadTask> ImageDownloadTasks { get; set; } /// <summary> /// 获得或设置是否已经完整下载过 /// </summary> public bool FullyDownloaded { get; set; } public TaskData() { PageDownloaded = new Dictionary<string, PageTask>(StringComparer.OrdinalIgnoreCase); DownloadedImages = new Dictionary<string, ImageDownloadTaskInfo>(StringComparer.OrdinalIgnoreCase); WaitForDownloadPageTasks = new Queue<PageTask>(); ImageDownloadTasks = new Queue<ImageDownloadTask>(); } }
当任务完成的时候,会从队列里出队,并放到已完成任务的字典中。
4.2 上下文环境
将所有的任务上下文抽象成一个单例对象,保存着所有的任务和相关设置。它负责啥事儿呢?
- 维护自己的一个单例对象
- 维护全局公用的上下文任务数据仓库
- 负责数据的存储和读取
由于这不是个很复杂的类,就直接贴出所有代码了。
class TaskContext { /// <summary> /// 数据目录 /// </summary> public string DataRoot { get; private set; } /// <summary> /// 下载目录 /// </summary> public string OutputRoot { get; set; } /// <summary> /// 任务数据 /// </summary> public TaskData Data { get; private set; } #region 单例模式 static TaskContext _instance; static readonly object _lockObject = new object(); public static TaskContext Instance { get { if (_instance == null) { lock (_lockObject) { if (_instance == null) { _instance = new TaskContext(); } } } return _instance; } } #endregion private TaskContext() { } /// <summary> /// 初始化 /// </summary> public void Init() { var root = System.Reflection.Assembly.GetExecutingAssembly().GetLocation(); DataRoot = PathUtility.Combine(root, "data"); OutputRoot = PathUtility.Combine(root, "下载"); Directory.CreateDirectory(DataRoot); Directory.CreateDirectory(OutputRoot); Data = LoadData<TaskData>("tasks.dat"); } /// <summary> /// 保存数据 /// </summary> public void Save() { SaveData(Data, "tasks.dat"); } /// <summary> /// 加载数据 /// </summary> /// <typeparam name="T"></typeparam> /// <param name="path"></param> /// <returns></returns> T LoadData<T>(string path) where T : class, new() { var file = PathUtility.Combine(DataRoot, path); if (File.Exists(file)) { return JsonConvert.DeserializeObject<T>(File.ReadAllText(file)); } return new T(); } /// <summary> /// 保存数据 /// </summary> /// <typeparam name="T"></typeparam> /// <param name="data"></param> /// <param name="path"></param> void SaveData<T>(T data, string path) { var file = PathUtility.Combine(DataRoot, path); Directory.CreateDirectory(Path.GetDirectoryName(file)); if (data == null) { File.Delete(file); } else File.WriteAllText(file, JsonConvert.SerializeObject(data)); } }
嗯……准备工作做完了。开始干正事儿
4.3 详细页面爬虫
详细页面爬虫的任务就是遍历所有的列表页,将每个详情页的地址和标题都抓出来。我们先看下列表页的HTML结构(戳这里看网页源码)。
<div class="m-post m-post-img "> <div class="ct"> <div class="ctc box"> <div class="pic"> <a class="img" href="http://sexy.faceks.com/post/2c9c66_59372b3"> <img src="http://imglf2.ph.126.net/Pqmu0SX94f3eShYmx9tHZw==/6619383255631059278.jpg" /> </a> </div> <div class="text"><p>ula 安静<br /></p></div> </div> </div> <div class="info"> <div class="lnks box"> <a class="date" href="http://sexy.faceks.com/post/2c9c66_59372b3">2015-01-27</a> <a class="hot" href="http://sexy.faceks.com/post/2c9c66_59372b3">27</a> </div> </div> </div>
作为有节操的码农,当然不会满足于简单粗暴地直接掀掉裙底;相反,他们一定会略带强迫症一般地按标题分门别类保存。
从上图我们可以看到,中间的一个 class="img" 的a标签是具体的页面地址,而 class="text" 的div标签则是文本内容。如何提取呢,最简单的就是用正则表达式了……这正则表达式知名度太高,这种事儿他做起来手到擒来 
div\sclass=['"]pic['"].*?href=['"]([^['"]+)['"].*?<p>([^<]+)<
抓取后,分组一是地址,分组二是标题……啊哈哈哈 
然后我们需要判断下一页。请观察这个网页的原始地址的源码我们会发现,它没有返回具体有多少页,只有一个下一页。可以推测的是,如果没有下一页了,这个链接会消失。在这种情况下,我们进化出了完善的遍历技能:
- 如果当前没有完全下载过,那么我们都从第一页开始往后面翻,直到翻到最后一页,然后标记已经完全下载过
- 如果已经完全下载过,那么看第一页有没有新纪录,如果有的话就继续看下一页,直到找到没有下一页或没有新纪录的页面,完成增量抓取
如何判断下一页呢?正则吧。
<a[^>]*?class=[""']next""[^>]*?href=['""][^>]*?page=\d+[""']
这个爬虫的完整代码如下。
#region 详情页抓取 /// <summary> /// 开始抓取详情页 /// </summary> async void GrabDetailPages(CancellationToken token) { AppendLog("[页面列表] 正在加载数据...."); //从第一页开始... var page = 1; var urlformat = "http://sexy.faceks.com/?page={0}"; //网络客户端 var client = new HttpClient(); var data = TaskContext.Instance.Data; while (!token.IsCancellationRequested) { AppendLog("[页面列表] 正在加载第 {0} 页", page); var ctx = client.Create<string>(HttpMethod.Get, urlformat.FormatWith(page)); await ctx.SendTask(); if (!ctx.IsValid()) { AppendLog("[页面列表] 第 {0} 页下载失败,稍后重试", page); await Task.Delay(new TimeSpan(0, 0, 10)); } else { //下载成功,获得列表 var matches = Regex.Matches(ctx.Result, @"div\sclass=['""]pic['""].*?href=['""]([^['""]+)['""].*?<p>([^<]+)<", RegexOptions.Singleline | RegexOptions.IgnoreCase); //新的任务 var newTasks = matches.Cast<Match>() .Select(s => new PageTask(s.Groups[2].Value, s.Groups[1].Value)) .Where(s => !data.PageDownloaded.ContainsKey(s.Url) && !data.WaitForDownloadPageTasks.Any(_ => _.Url == s.Url)) .ToArray(); if (newTasks.Length > 0) { lock (data.WaitForDownloadPageTasks) { newTasks.ForEach(s => { data.WaitForDownloadPageTasks.Enqueue(s); }); } AppendLog("[页面列表] 已建立 {0} 新任务到队列中...", newTasks.Length); UpdatePageDetailGrabStatus(); } else if (data.FullyDownloaded) { //没有更多记录,退出循环 AppendLog("[页面列表] 没有更多新纪录,退出抓取..."); break; } //如果没有下一页,则中止 if (!Regex.IsMatch(ctx.Result, @"<a[^>]*?class=[""']next""[^>]*?href=['""][^>]*?page=\d+[""']", RegexOptions.IgnoreCase)) { AppendLog("[页面列表] 没有更多的页面,退出抓取..."); data.FullyDownloaded = true; break; } //等待2秒继续 await Task.Delay(new TimeSpan(0, 0, 2)); page++; } } AppendLog("[页面列表] 页面任务抓取完成..."); } #endregion
几个要点提示:
- 这里使用了
async和await异步任务模式。其实这个爬虫完全是异步执行的,可以不用async和await(相应的SendTask()应该改成Send()) - 每读取一个页面后我们很友好地等待了2秒钟没有连续读取。这里的等待也是异步任务,完全可以改成
Thread.Sleep()
这中间有两个辅助函数,一个是AppendLog,一个是UpdatePageDetailGrabStatus()。前一个是向日志文本框中添加日志用的,后一个则是更新当前页面抓取任务进度用的。他们的定义如下。
/// <summary> /// 添加日志 /// </summary> /// <param name="message"></param> /// <param name="args"></param> void AppendLog(string message, params object[] args) { if (InvokeRequired) { Invoke(new Action(() => { AppendLog(message, args); })); return; } if (args == null || args.Length == 0) { txtLog.AppendText(message); } else { txtLog.AppendText(string.Format(message, args)); } txtLog.AppendText(Environment.NewLine); txtLog.ScrollToCaret(); }
/// <summary> /// 更新页面抓取进度 /// </summary> void UpdatePageDetailGrabStatus() { if (InvokeRequired) { Invoke(new Action(UpdatePageDetailGrabStatus)); return; } var data = TaskContext.Instance.Data; pgPage.Maximum = data.WaitForDownloadPageTasks.Count + data.PageDownloaded.Count; pgPage.Value = pgPage.Maximum - data.WaitForDownloadPageTasks.Count; lblPgSt.Text = string.Format("共 {0} 页面,已抓取 {1} 页面 ...", pgPage.Maximum, pgPage.Value); }
4.4 图片地址爬虫
详情页列表任务成功地把美女们所在的房间按照类别送过来了,那还等啥,直接过去爬吧。
拿到地址后先看看源码,比如戳这里看示例。
<div class="ct"> <div class="ctc box"> <div class="pic"> <a href="#" class="img imgclasstag" imggroup="gal" bigimgwidth="1343" bigimgheight="1940" bigimgsrc="http://imglf1.ph.126.net/-crOhBNS6jD4VQZZEJq33A==/6630244231489313026.jpg"> <img src="http://imglf1.ph.126.net/-crOhBNS6jD4VQZZEJq33A==/6630244231489313026.jpg"/> </a> </div> <div class="pic"> <a href="#" class="img imgclasstag" imggroup="gal" bigimgwidth="1343" bigimgheight="1940" bigimgsrc="http://imglf2.ph.126.net/f4-wuLEbcWX9LdXhwCSMYQ==/6619383255631055372.jpg"> <img src="http://imglf2.ph.126.net/f4-wuLEbcWX9LdXhwCSMYQ==/6619383255631055372.jpg"/> </a> </div> <div class="pic"> <a href="#" class="img imgclasstag" imggroup="gal" bigimgwidth="1343" bigimgheight="1940" bigimgsrc="http://imglf0.ph.126.net/lG7nmlYYGi0yNiRT71TFQg==/6630848962884609045.jpg"> <img src="http://imglf0.ph.126.net/lG7nmlYYGi0yNiRT71TFQg==/6630848962884609045.jpg"/> </a> </div> <div class="pic"> <a href="#" class="img imgclasstag" imggroup="gal" bigimgwidth="1343" bigimgheight="1940" bigimgsrc="http://imglf1.ph.126.net/drA7UofDdVmP40y9ksNeZw==/6630483925024168480.jpg"> <img src="http://imglf1.ph.126.net/drA7UofDdVmP40y9ksNeZw==/6630483925024168480.jpg"/> </a> </div> <div class="pic"> <a href="#" class="img imgclasstag" imggroup="gal" bigimgwidth="1343" bigimgheight="1940" bigimgsrc="http://imglf2.ph.126.net/wJIpPSaG3cyFF7fVoROS0Q==/6619566874072895897.jpg"> <img src="http://imglf2.ph.126.net/wJIpPSaG3cyFF7fVoROS0Q==/6619566874072895897.jpg"/> </a> </div> <div class="pic"> <a href="#" class="img imgclasstag" imggroup="gal" bigimgwidth="1343" bigimgheight="1940" bigimgsrc="http://imglf0.ph.126.net/-t8Hn7nnIH1TmE_lxYXfYQ==/6630122185698630036.jpg"> <img src="http://imglf0.ph.126.net/-t8Hn7nnIH1TmE_lxYXfYQ==/6630122185698630036.jpg"/> </a> </div> <div class="text"><p>yanni 蓝色妖姬<br /></p></div> </div> </div>
……真是简单到完全没有任何保护措施啊,也不怕有人心存歹念 
这代码应该看得很明显,我们直接找 bigimgsrc="" 就能看到大图了。正则表达式伺候。
bigimgsrc=["']([^'"]+)['"]
这部分源码如下,参考注释。
void GrabImageListTaskThreadEntry(CancellationToken token) { var client = new HttpClient(); var data = TaskContext.Instance.Data; PageTask currentTask; //token是用来控制队列退出的 while (!token.IsCancellationRequested) { currentTask = null; //对队列进行加锁,防止详情页爬虫意外修改队列 lock (data.WaitForDownloadPageTasks) { //如果有任务,则出队 if (data.WaitForDownloadPageTasks.Count > 0) { currentTask = data.WaitForDownloadPageTasks.Dequeue(); } } //如果没有任务,则等待100毫秒后继续查询任务 if (currentTask == null) { Thread.Sleep(100); continue; } AppendLog("[详情页抓取] 正在抓取页面 【{0}】 ...", currentTask.Name); //防止该死的标题过长……这个是后来加的,因为后拉发现有的标题居然长到让文件系统报错了…… currentTask.Root =currentTask.Name.GetSubString(40); //创建上下文。注意 allowAutoRedirect,因为这里可能会存在重定向,而我们并不关心不是302. var ctx = client.Create<string>(HttpMethod.Get, currentTask.Url, allowAutoRedirect: true); //这里用的是同步模式,非任务模式。这个方法会阻塞当前线程直到请求结束 ctx.Send(); if (ctx.IsValid()) { //页面有效 var html = ctx.Result; //查出所有姑娘的地址,然后与已下载和已入列的对比,排除重复后将其加入下载队列 var imgTasks = Regex.Matches(html, "bigimgsrc=[\"']([^'\"]+)['\"]", RegexOptions.IgnoreCase | RegexOptions.Singleline) .Cast<Match>().Select(s => new ImageDownloadTask(s.Groups[1].Value, currentTask.Root)) .Where(s => { var ret = !data.DownloadedImages.ContainsKey(s.Url) && !data.ImageDownloadTasks.Any(_ => _.Url == s.Url); if (!ret) { AppendLog("[详情页抓取] 图片地址 {0} 已加入队列过,此次跳过.", s); } return ret; }) .ToArray(); if (imgTasks.Length > 0) { lock (data.ImageDownloadTasks) { imgTasks.ForEach(task => { data.ImageDownloadTasks.Enqueue(task); }); } UpdateImageDownloadStatus(); AppendLog("[详情页抓取] 从页面 【{0}】中获得 {1} 图片地址到任务列表 ...", currentTask.Url, imgTasks.Length); } else { AppendLog("[详情页抓取] 从页面 【{0}】中未获得任何图片地址,请检查是否正常 ...", currentTask.Url); } data.PageDownloaded.Add(currentTask.Url, currentTask); UpdatePageDetailGrabStatus(); } else { //不成功,则将当前任务重新入队后,继续处理 lock (data.WaitForDownloadPageTasks) { data.WaitForDownloadPageTasks.Enqueue(currentTask); } UpdatePageDetailGrabStatus(); Thread.Sleep(2000); AppendLog("[详情页抓取] 页面抓取失败,重新入队等待处理。"); } } }
中间有个 UpdatePageDetailGrabStatus 函数,这同样是个更新界面显示的函数。
/// <summary> /// 更新页面抓取进度 /// </summary> void UpdateImageDownloadStatus() { if (InvokeRequired) { Invoke(new Action(UpdateImageDownloadStatus)); return; } var data = TaskContext.Instance.Data; pgPicDownload.Maximum = data.DownloadedImages.Count + data.ImageDownloadTasks.Count; pgPicDownload.Value = pgPicDownload.Maximum - data.ImageDownloadTasks.Count; lblStatPicDownload.Text = string.Format("共 {0} 图片,已抓取 {1} 图片 ...", pgPicDownload.Maximum, pgPicDownload.Value); }
4.5 图片下载队列
……没啥花头,直接上代码。参见注释。
async void DownloadImageTaskEntry(CancellationToken token) { var client = new HttpClient(); var data = TaskContext.Instance.Data; var random = new Random(); var cleanupcount = 0; //这里创建了一个 CancellationTokenSource 的局部变量,主要是为了在循环中对请求也能进行中断 CancellationTokenSource tcs = null; token.Register(() => tcs?.Cancel()); ImageDownloadTask task; while (!token.IsCancellationRequested) { task = null; //检查下载队列,看是否有姑娘的地址搭讪到了…… lock (data.ImageDownloadTasks) { if (data.ImageDownloadTasks.Count > 0) { task = data.ImageDownloadTasks.Dequeue(); } } //没有或已经下载过的话,则休息后重新检查 if (task == null || data.DownloadedImages.ContainsKey(task.Url)) { Thread.Sleep(100); continue; } //开始下载 AppendLog("[图片下载] 正在下载自 {0} ...", task.Url); using (var ctx = client.Create<byte[]>(HttpMethod.Get, task.Url)) { //这里的token必须用新的,否则会导致内存短期内无法释放,内存暴涨 tcs = new CancellationTokenSource(); await ctx.SendTask(tcs.Token); tcs = null; if (ctx.IsValid()) { //成功,保存。优先取URL地址中的文件名作为保存的文件名 var targetFileName = new Uri(task.Url).Segments.LastOrDefault(); //如果文件名不合法,则重新生成随机的文件名 if (targetFileName.IsNullOrEmpty() || targetFileName.Length > 50 || Path.GetInvalidFileNameChars().Any(s => targetFileName.Contains(s))) { //包含无效的文件名,则重新生成随机的 targetFileName = DateTime.Now.ToString("yyyyMMddHHmmss") + random.Next(int.MaxValue) + ".jpg"; } //....这个if是冗余的,因为重构前任务的保存地址被设置成绝对地址了。但是后来两台机器之间转移时发现下载就错位了 //所以后来改成保存相对地址。但是之前的任务文件懒得手动改,所以加个冗余做检测 if (Path.IsPathRooted(task.DownloadRoot)) { var dirName = Path.GetFileName(task.DownloadRoot); if (dirName.Length > 40) task.DownloadRoot = PathUtility.Combine(Path.GetDirectoryName(task.DownloadRoot), dirName.Substring(0, 40)); } else { //需要判断长度是因为之前没判断,结果他喵的有超长的…… task.DownloadRoot =task.DownloadRoot.Length > 40 ? task.DownloadRoot.Substring(0, 40) : task.DownloadRoot; } //如果文件夹不存在,则创建 if (!Directory.Exists(task.DownloadRoot)) Directory.CreateDirectory(task.DownloadRoot); //写入文件 var targetFullPath = PathUtility.Combine(task.DownloadRoot, targetFileName); File.WriteAllBytes(targetFullPath, ctx.Result); //添加到已完成队列 data.DownloadedImages.Add(task.Url, new ImageDownloadTaskInfo() { Location = targetFullPath }); //记录 AppendLog("[图片下载] 下载成功. ({0})", ctx.Result.Length.ToSizeDescription()); } else { lock (data.ImageDownloadTasks) { data.ImageDownloadTasks.Enqueue(task); } AppendLog("[图片下载] 下载失败。重新加入队列以便于重新下载"); } } UpdateImageDownloadStatus(); //等待一秒再下下一个姑娘,虽然精虫上脑但咱是有尊严的码农! await Task.Delay(1000, token); if (cleanupcount++ > 20) { //每下载20个美女后手动释放一下内存 cleanupcount = 0; GC.Collect(); //保存任务数据,防止什么时候宕机了任务进度回滚太多 TaskContext.Instance.Save(); } } }
4.6 任务启动
代码都写完了,还要干嘛?当然是启动。直到现在这些任务还是分离的,当然要有函数去启动它。
首先是Button点击的响应。
public MainForm() { InitializeComponent(); btnGo.Click += (s, e) => { btnGo.Enabled = false; RunTask(); }; }
从简化开发的角度出发,这里设计按钮只允许点击一次……启动就是启动了……就不给你重新点击……
/// <summary> /// 设置是否允许关闭的标记位 /// </summary> bool _shutdownFlag = false; void RunTask() { btnGo.Enabled = false; var cts = new CancellationTokenSource(); AppendLog("[全局] 正在初始化..."); TaskContext.Instance.Init(); AppendLog("[全局] 初始化完成..."); AppendLog("[全局] 启动图片下载任务..."); var imgDownloadToken = new Task(() => DownloadImageTaskEntry(cts.Token), cts.Token, TaskCreationOptions.LongRunning); imgDownloadToken.Start(); AppendLog("[全局] 图片下载任务已启动..."); AppendLog("[全局] 启动详情页下载任务..."); var pageDownloadTask = new Task(() => GrabImageListTaskThreadEntry(cts.Token), cts.Token, TaskCreationOptions.LongRunning); pageDownloadTask.Start(); AppendLog("[全局] 详情页下载任务已启动..."); AppendLog("[全局] 启动详情页抓取任务..."); var detailPageGrab = new Task(() => GrabDetailPages(cts.Token), cts.Token, TaskCreationOptions.LongRunning); detailPageGrab.Start(); AppendLog("[全局] 详情页抓取任务已启动..."); //捕捉窗口关闭事件 //主要是给一个机会等待任务完成并把任务数据都保存 FormClosing += async (s, e) => { if (_shutdownFlag) return; e.Cancel = !_shutdownFlag; AppendLog("[全局] 等待任务结束..."); cts.Cancel(); try { await detailPageGrab; await pageDownloadTask; await imgDownloadToken; } catch (Exception) { } _shutdownFlag = true; TaskContext.Instance.Save(); Close(); }; }
4.7 收工
以上基本上包含了全部的代码,编译没有错误的话,就点击开工然后等着妹子来到你的硬盘吧!咩哈哈……
5. 尾声
附带唠叨点什么吧。
我收集美女图的历史要追溯到大一的时候,那会儿流行BT,收集了不少美女图。不过大二的时候觉得他们都太过于庸俗,所以全部都删掉了。在那之后直到现在,再也没有收藏过什么美女图。
现在居然又觉得美女图看看还不错的话,我真应该好好琢磨一下自己的心理都发生啥变化了……
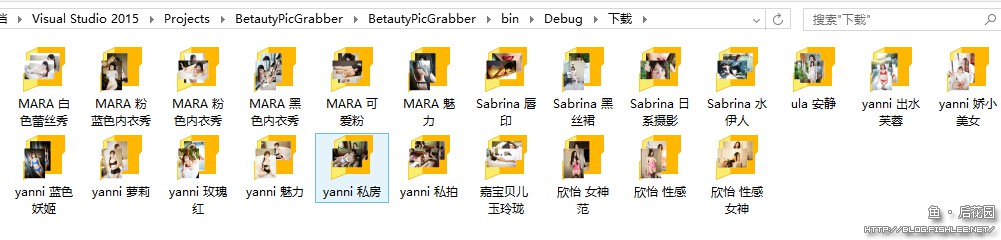
反正图片都拖完了,你们随意……嗯啊,反正我已经拖下来3.82G的图片了,你们折腾吧我去掀牌儿了…… 
感谢阅读本文,欢迎扫描下方二维码关注鱼的公众号(微信内长按识别哦) 

木鱼大哥你好,我想通过http://xui.ptlogin2.qq.com/cgi-bin/qlogin?domain=qq.com&lang=2052&qtarget=1&jumpname=&appid=549000912&ptcss=undefined¶m=u1%253Dhttp%25253A%25252F%25252Fqun.qzone.qq.com%25252Fgroup&css=&mibao_css=&s_url=http%253A%252F%252Fqun.qzone.qq.com%252Fgroup&low_login=0&style=12&authParamUrl=&needVip=1&ptui_version=10028
这个url抓取本机已登入的qq号,用.net4.0 WebBrowser或HttpWebRequest抓取的时候list_uin是空的,而我直接用浏览器访问却是有数据的。我是菜鸟哈
webbrowser应该有吧。这个list_uin是动态加载的,你需要动态去获取,初始化加载是无法获得的。
具体的可以搜索一下本博客,大概2010年3-4月有几篇博客提到了这个。
鱼大你的代码都引用了那些库呢?能贴下吗?最好是分享下工程。我用的SharpDevelop5.1,提示“System.Net.Http.HttpClient”不包含“Create”的定义,并且找不到可接受类型为“System.Net.Http.HttpClient”的第一个参数的扩展方法“Create”(是否缺少 using 指令或程序集引用?),错误代码是[var ctx = client.Create(HttpMethod.Get, urlformat.FormatWith(page));],求解。谢谢
这个项目引用的库就是我的已开源的俩库以及JSON.NET啊,没有其它的依赖。你可以看看引用的FSLIB.NETWORK中HttpClient具体的方法签名并对比下。
鱼大我引用了这些库,[using System;using System.Collections.Generic;using System.Drawing;using System.IO;using System.Text.RegularExpressions;using System.Threading;using System.Threading.Tasks;using System.Web;usingSystem.Windows.Forms;using FSLib.Network;using Newtonsoft.Json;using FSLib.Extension;],提示命名空间“FSLib”中不存在类型或命名空间名称“Extension”(是否缺少程序集引用?),鱼大求分享您的工程,我实在是搞不定。谢谢
FSLIB.EXTENSION 这个库你没装吧?
谢谢鱼大解答,代码已调试成功了
:idea:赞,顶一个。。。
我在想是不是把抓美女图程序改下,把你的博客全部Down下来呢?
哎呀,真是太牛逼啦
https://msdn.microsoft.com/en-us/library/system.web.httputility.htmldecode(v=vs.110).aspx
在非web应用程序中使用HtmlDecode方法需要引用WebUtity。
中间那个HttpUtity需要更改一下
我就一说。。
感谢告知
这个库是4.0的framework才有的。所以不能用。还是继续用system.web下的吧。
我就想起来了补充一下。
用vs2010 修改了些代码 结果运行不了啊 停在那了~ 大侠能不能直接上源码 😳
逼不得已用了2012加framework4.5 可以运行 只是列表页总是下载29页~ 懒得没救了
总是在下载29页?调试咯。
第一次和活的大牛对话感觉好激动啊~ 木鱼大哥是在公司上班麽 还是投入到如火如荼的创业大军了
没能力创业。。
网址已拿走 回头把程序也拿走
图片太重口味了
能不能抓QQ相册的?
这个库只是基础服务不涉及应用。不过说一嘴QQ相册可以用QQ影像下载。
不错,鱼大 可以搞几个WP程序嘛
话说这里的
—-
//这里创建了一个 CancellationTokenSource 的局部变量,主要是为了在循环中对请求也能进行中断
CancellationTokenSource tcs = null;
token.Register(() => tcs?.Cancel());
—–
tcs?.Cancel()是什么写法?编译有问题,先去掉了
这个是最新的C#6的写法。等效于
if(tcs!=null) tcs.Cancel();鱼大的精神可嘉,持续的研究新的语法呀…
http://huyisong123.lofter.com 这个怎么就不能下载了呢
这不是同一个站吧。。。
嗯。 的确不是一个站。但是结构貌似差不多的吧。 你的代码已经跑起来了,然后把地址换成这个就搞不到数据了 = =
很明显不能直接用。。
这样啊。。。。。
.net框架要选4.5啊 = = 真高
可以用3.5-4.0,个别写法需要换一下。
vs2010+4.0异步这一块需要怎么写,好像不支持async啊
看到鱼大写的提示了,都怪我光顾看美女了:roll:
全部COPY 下来了。。 理解起来有点困难啊 = =
JoinAsString 这是什么
http://sexy.faceks.com/sitemap.xml 用这个好不好点呢
你这个不错,都是美女图
程序怎么不放出来啊
不要以为我不知道,程序放出来乃们这群混蛋只会拿了程序走人~
哈哈,鱼大聪明,不过看完这帖子,我决定去浏览网站了,
。。。鱼大的帖子治好了我多年的不孕不育。。。
啊啊啊啊都在爬美女图。
只看到一个链接有用
我还以为是可以智能识别是不是美女图呢!! 我就想知道这个审美标准是怎么实现的. 点进来才知道原来有这么好的一个网址, 哎呀, 我又发现了不得了的东西. 至于代码什么, 谁管它呀.
看不懂才是厉害的。。。。